The Lloyd Sealy Library website uses Drupal 7 as its content management system and Git for version control. The tricky thing about this setup is that you can keep track of some parts of a Drupal site using Git, but not all. Code can be tracked in Git, but content can’t be.
Code
- theme files (CSS, PHP, INC, etc.)
- the out-of-the-box system
- all modules
- any core or module updates (do on dev, push to production)
Content
- anything in the Drupal database:
- written content (pages, blog posts, menus, etc.)
- configurations (preferences, blocks, regions, etc.)
Here’s our workflow:
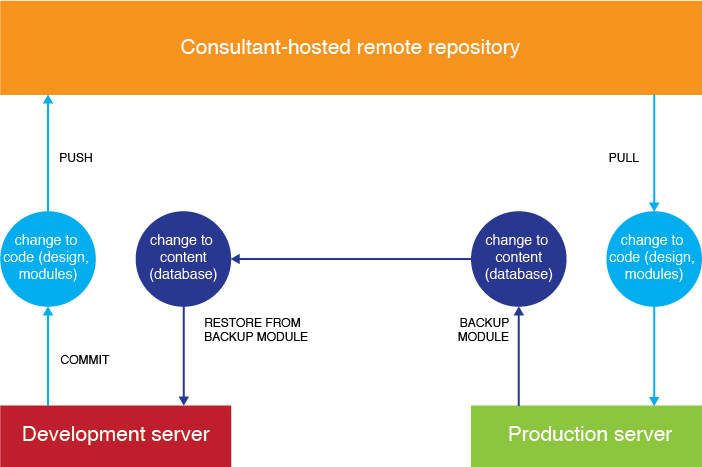
Code: Using Git to push code from dev to production is pretty straightforward. I was a SVN gal, so getting used to the extra steps in Git took some time to learn. I used video tutorials made by our consultants at Cherry Hill as well as Lynda.com videos. (For those new to using version control, it’s a mandatory practice if you manage institutional websites. Using version control between two servers lets you work on the same content simultaneously with other people and roll out changes in a deliberate manner. Version control keeps track of all the changes made over time, too, so if you mess up, you can easily revert your site back to a safe version.)
Content: Keeping the content up to date on both servers is a little hairier. We use the Backup and Migrate module to update our dev database on an irregular schedule with new content made on the production server. The only reason to update the dev database is so that our dev and production sites aren’t confusingly dissimilar. Additionally, some CSS might refer to classes newly specified in the database content. The schedule is irregular because the webmaster, Mandy, and I sometimes test out content on the dev side first (like a search box) before copying the content manually onto the production site.
Why have a two-way update scheme? Why not do everything on dev first, and restore the database from dev to production? We want most content changes to be publicly visible immediately. All of our librarians have editor access, which was one of the major appeals of using a CMS that allowed different roles. Every librarian can edit pages and write blog posts as they wish. It would be silly to embargo these content additions.
Help: A lot of workflow points are covered in Drupal’s help page, Building a Drupal site with Git. As with all Drupal help pages, though, parts of it are incomplete. The Drupal4Lib listserv is very active and helpful for both general and library-specific Drupal questions.
Non-Drupal files: Lastly, we have some online resources outside of Drupal that we don’t want clogging up our remote repository, like the hundreds of trial transcript PDFs. These aren’t going to be changing, and they’re not code. The trial transcript directory is therefore listed in our .gitignore file.
Any Drupal/Git workflow tips?