TL;DR: A hacker uploaded a fake JPG file containing PHP code that generated “invisible” spam blog posts on our website. To avoid this happening to you, block inactive accounts in Drupal and monitor Google Search Console reports.
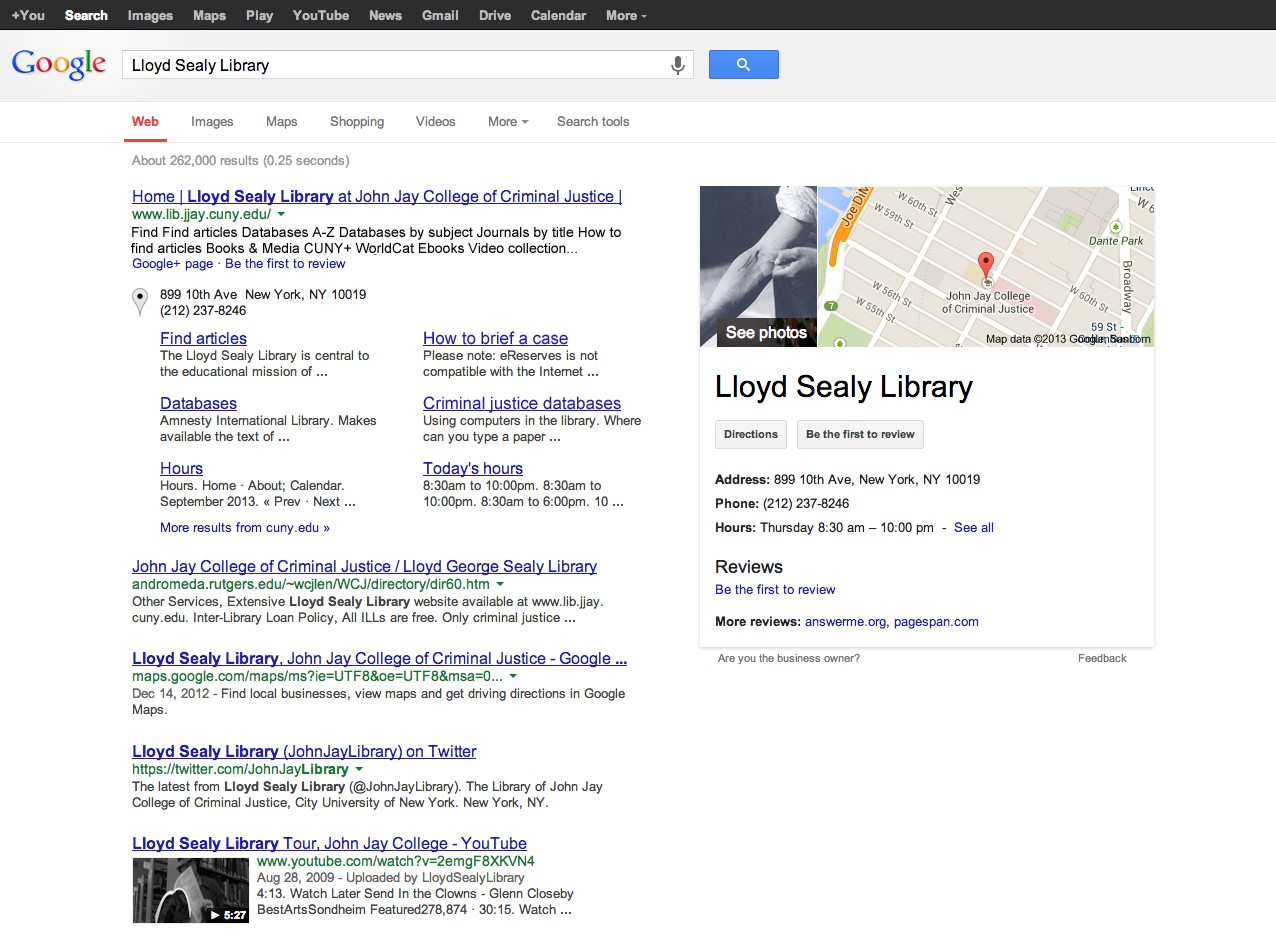
I noticed something odd on the library website the other day: a search of our site displayed a ton of spam in the Google Custom Search Engine (CSE) results.
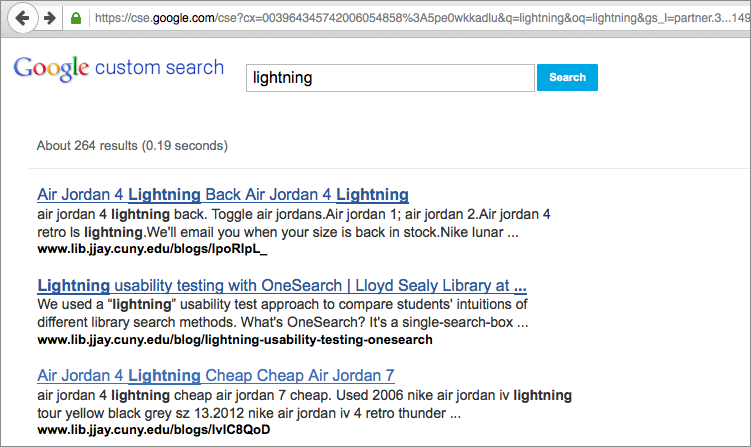
But when I clicked on the links for those supposed blog posts, I’d get a 404 Page Not Found error. It was like these spammy blog posts didn’t seem to exist except for in search results. I thought this was some kind of fake-URL generation visible just in the CSE (similar to fake referral URLs in Analytics), but regular Google was seeing these spammy blog posts as being on our site as well if I searched for an exact title.
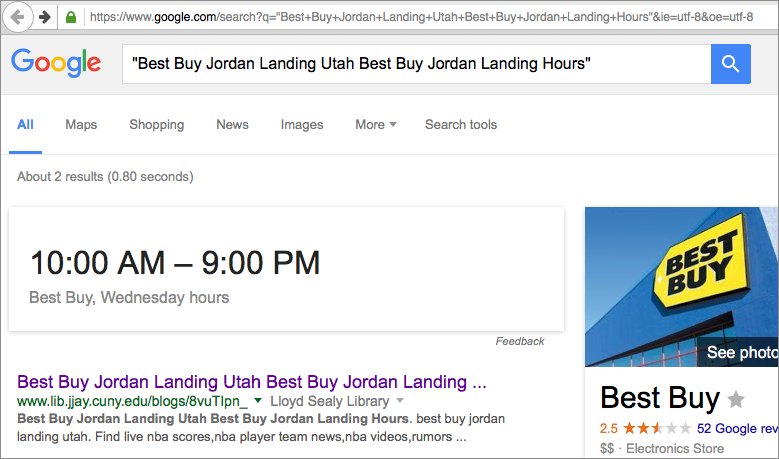
Still, Google was “seeing” these blog posts that kept netting 404 errors. I looked at the cached page, however, and saw that Google had indexed what looked like an actual page on our site, complete with the menu options.
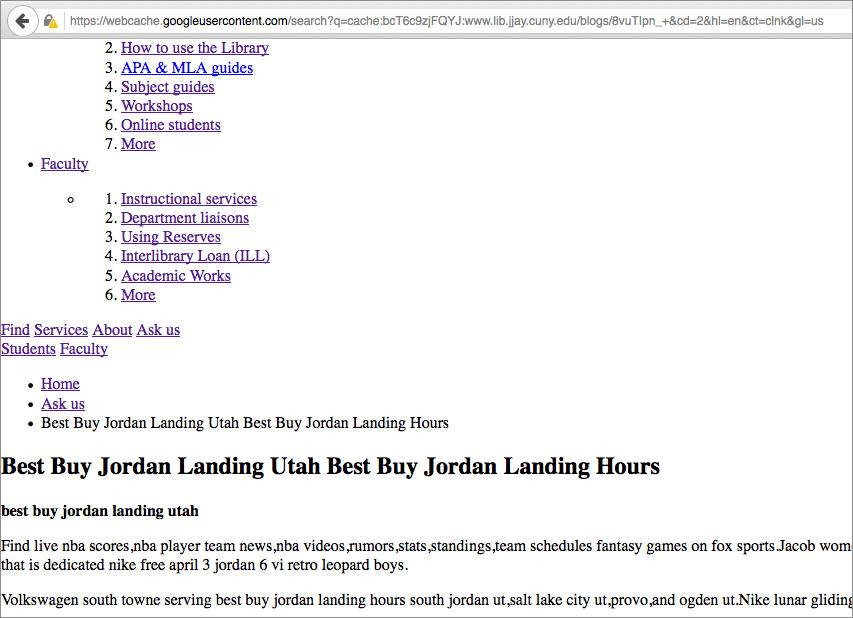
Cloaked URLs
Not knowing much more, I had to assume that there were two versions of these spam blog posts: the ones humans saw when they clicked on a link, and the ones that Google saw when its bots indexed the page. After some light research, I found that this is called “cloaking.” Google does not like this, and I eventually received an email from Webmaster Tools with the subject “Hacked content detected.”
It was at this point that we alerted the IT department at our college to let them know there was a problem and that we were working on it (we run our own servers).
Finding the point of entry
Now I had to figure out if there was actually content being injected into our site. Nothing about the website looked different, and Drupal did not list any new pages, but someone was posting invisible content, purely to show up in Google’s search results and build some kind of network of spam content. Another suspicious thing: these URLs contained /blogs/, but our actual blog posts have URLs with /blog/, suggesting spoofed content. In Drupal, I looked at all the reports and logs I could find. Under the People menu, I noticed that 1 week ago, someone had signed into the site with a username for a former consultant who hadn’t worked on the site in two years.
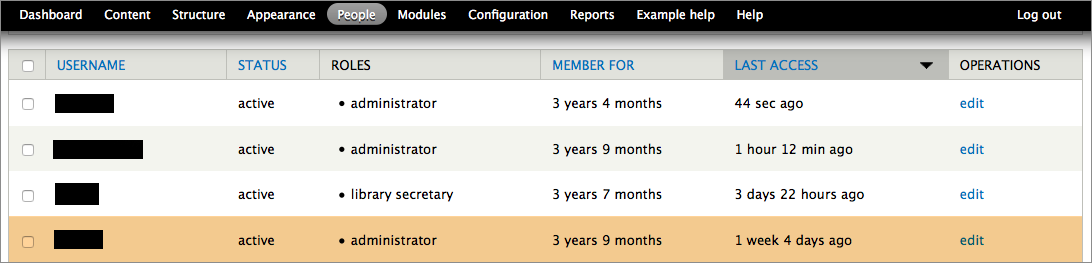
Yikes. So it looks like someone had hacked into an old, inactive admin account. I emailed our consultant and asked if they’d happened to sign in, and they replied Nope, and added that they didn’t even like Nikes. Hmm.
So I blocked that account, as well as accounts that hadn’t been used within the past year. I also reset everyone’s passwords and recommended they follow my tips for building a memorable and hard-to-hack password.
Clues from Google Search Console
The spammy content was still online. Just as I was investigating the problem, I got this mysterious message in my inbox from Google Search Console (SC). Background: In SC, site owners can set preferences for how their site appears in Google search results and track things like how many other websites like to their website. There’s no ability to change the content; it’s mostly a monitoring site.
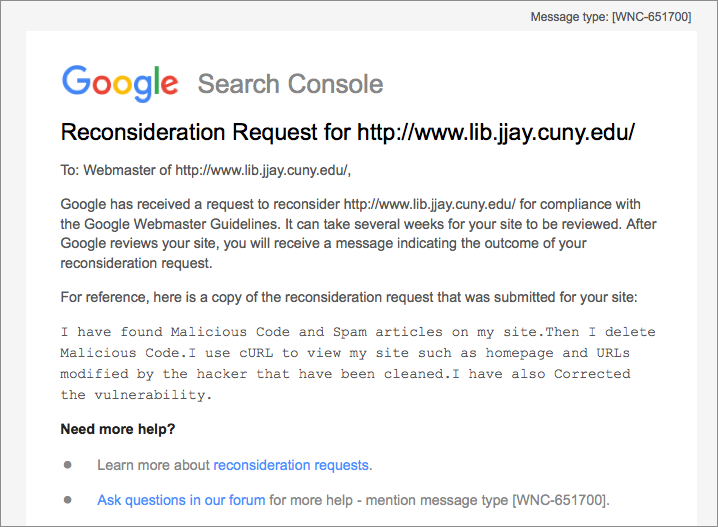
I didn’t write that reconsideration request. Neither did our webmaster, Mandy, or anybody who would have access to the Search Console. Lo and behold, the hacker had claimed site ownership in the Search Console:
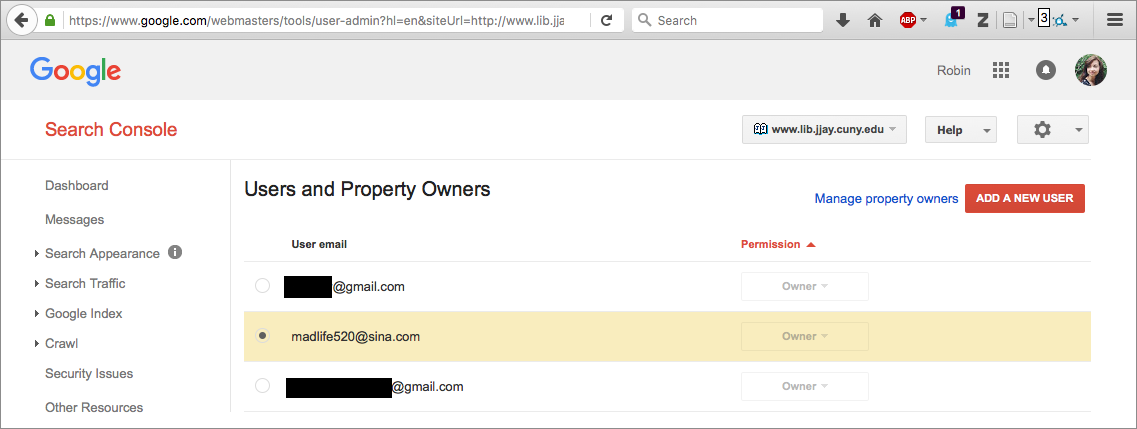
Now our hacker had a name: Madlife520. (Cool username, bro!) And they’d signed up for SC, probably because they wanted stats for how well their spam posts were doing and to reassure Google that the content was legit.
But Search Console wouldn’t let me un-verify Madlife520 as a site owner. To be a verified site owner, you can upload a special HTML file they provide to your website, with the idea that only a true site owner would be able to do that.
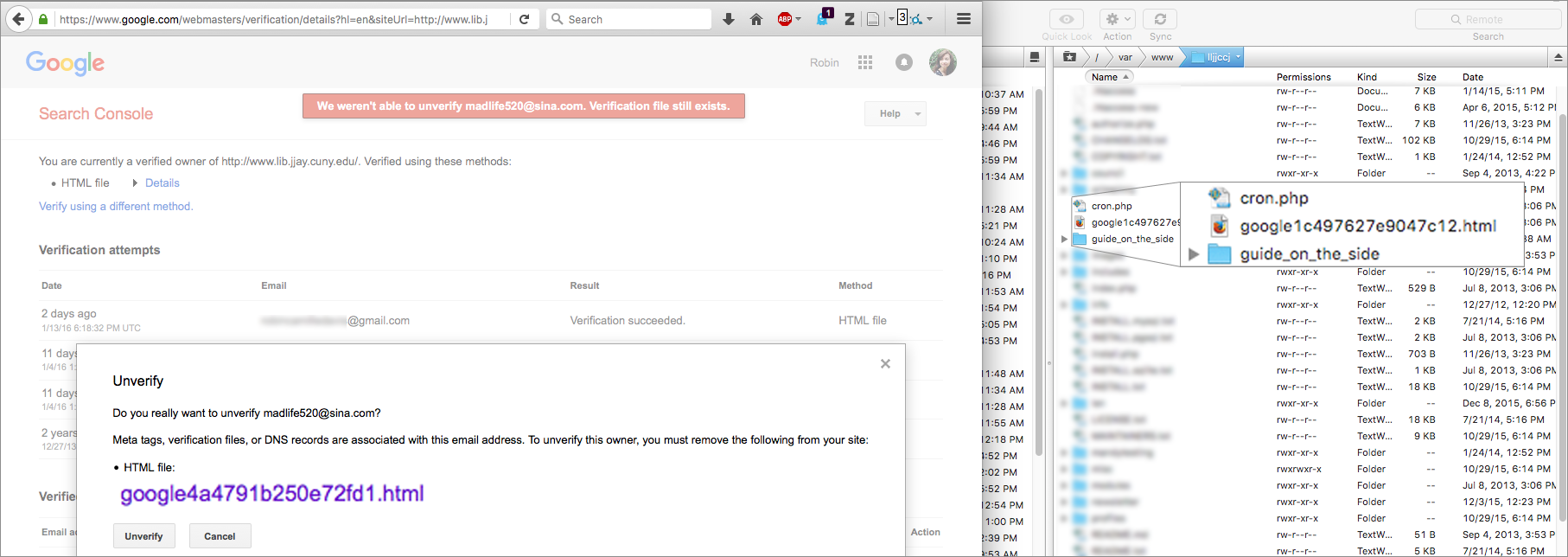
But here’s where I felt truly crazy. Google said Madlife520’s verification file was still online. But we couldn’t find it! The only verification file was mine (ending in c12.html, not fd1.html). Another invisible file. What was going on? Why couldn’t we see what Google could see?
Finding malicious code
Geng, our whipsmart systems manager, did a full-text search of the files on our server and found the text string google4a4…fd1.html in the contents of a JPG file in …/private/default_images/. Yep, not the actual HTML file itself, but a line in a JPG file. Files in /private/ are usually images uploaded to our slideshow or syllabi that professors send through our schedule-a-class webform — files submitted through Drupal, not uploaded directly to the server.
So it looks like this: Madlife520 had logged into Drupal with an inactive account and uploaded a text file with a .JPG extension to a module or form (not sure where yet). This text file contained PHP code that dictated that if Google or other search engines asked for the URL of these spam blog posts, the site would serve up spammy content from another website; if a person clicked on that URL, it would display a 404 Page Not Found page. Moreover, this PHP code spoofed the Google Search Console verification file, making Google think it was there when it actually wasn’t. All of this was done very subtly — aside from weird search results, nothing on the site looked or felt differently, probably in the hope that we wouldn’t notice anything unusual so the spam could stay up for as long as possible.
Steps taken to lock out the hacker
Geng saved a local file of the PHP code, then deleted it from the server. He also made the subdirectory they were in read-only. Mandy, our webmaster, installed the Honeypot module in Drupal, which adds an invisible “URL: ___” field to all webforms that bots will keep trying to fill without ever successfully logging in or submitting a form, in case that might prevent password-cracking software. On my end, I blocked all inactive Drupal accounts, reset all passwords, unverified Madlife520 from Search Console, and blocked IPs that had attempted to access our site a suspiciously high number of times (these IPs were all in a block located in the Netherlands, oddly).
At this point, Google is still suspicious of our site:
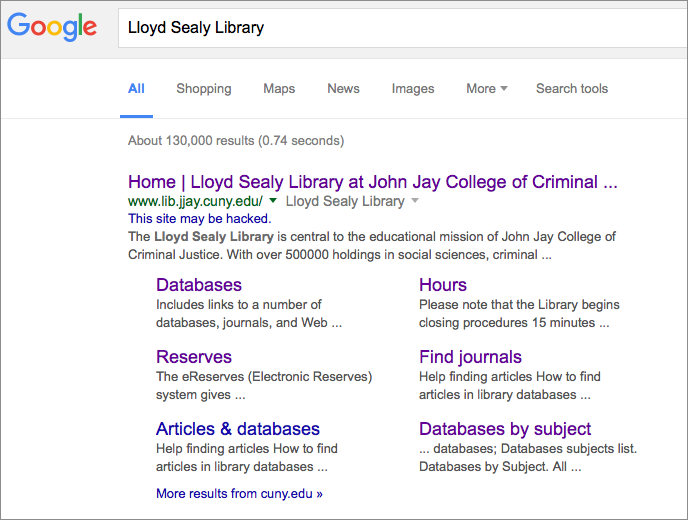
But I submitted a Reconsideration Request through Search Console — this time, actually written by me.
And it seems that the spammy content is no longer accessible, and we’re seeing far fewer link clicks on our website than before these actions.
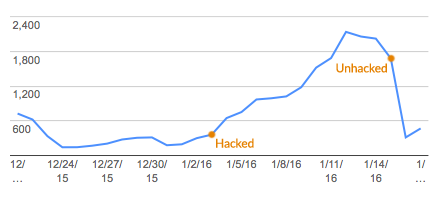
I’m happy that we were able to curb the spam and (we hope) lock out the hacker in just over a week, all during winter break when our legitimate traffic is low. We’re continuing to monitor all the pulse points of our site, since we don’t know for sure there isn’t other malicious code somewhere.
I posted this in case someone, somewhere, is in their office on a Friday at 5pm, frantically googling invisible posts drupal spam urls 404??? like I was. If you are, good luck!