In my ongoing experiments with my Raspberry Pi, I’ve been looking for small ways it can be useful for the library. I’ve been controlling my Pi remotely using SSH in Terminal (tutorial — though you’ll have to note your Pi’s IP address first). As I noted yesterday, I’ve been making it tweet, but was looking to have it share information more interesting than a temperature or light reading. So now I have the Pi tweeting our library’s hours on my test account:
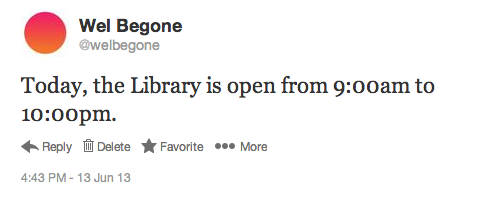
To do this, I installed BeautifulSoup, a Python library for working with HTML. My Python script uses BeautifulSoup to search the library’s homepage and find two spans with the classes date-display-start and date-display-end. (This is looking specifically at a view in Drupal that displays our daily hours.) Then it grabs the content of those spans and plunks it into a string to tweet. Here’s the script:
#!/usr/bin/env python
import tweepy
from bs4 import BeautifulSoup
import urllib3CONSUMER_KEY = '********************' #You'll have to make an application for your Twitter account
CONSUMER_SECRET = '********************' #Configure your app to have read-write access and sign in capability
ACCESS_KEY = '********************'
ACCESS_SECRET = '********************'auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET)
auth.set_access_token(ACCESS_KEY, ACCESS_SECRET)
api = tweepy.API(auth)http = urllib3.PoolManager()
web_page = http.request('GET','http://www.lib.jjay.cuny.edu/')
web_page_data = web_page.datasoup = BeautifulSoup(web_page_data)
openh = soup.find('span','date-display-start') #spans as defined in Drupal view
closedh = soup.find('span','date-display-end')
other = soup.find('span','date-display-single')if openh: #if library is open today, tweet and print hours
openh = openh.get_text() + ' to '
closedh = closedh.get_text()
api.update_status("Today's Library hours: " + openh + closedh + '.')
print "Today's Library hours: " + openh + closedh + '.'
elif other: #if other message (eg Closed), tweet and print
other = other.get_text()
api.update_status("Today's Library hours: " + other + '.')
print "Today's Library hours: " + other + '.'
else:
print "I don't know what to do."
Python libraries used:
- BeautifulSoup (Python + HTML)
- urllib3 (Python + internet)
- Tweepy (Python + Twitter)
I’ve configured cron to post at 8am every morning:
sudo crontab -e
[I added this line:]
00 8 * * * python /home/pi/Projects/Twitter/libhours-johnjaylibrary.py
Notes: I looked at setting up an RSS feed based on the Drupal view, since web scraping is clunky, but no dice. Also, there’s no real reason why automated tweeting has to be done on the Pi rather than a regular ol’ computer, other than I’d rather not have my iMac on all the time. And it’s fun.