5:50pm, Friday
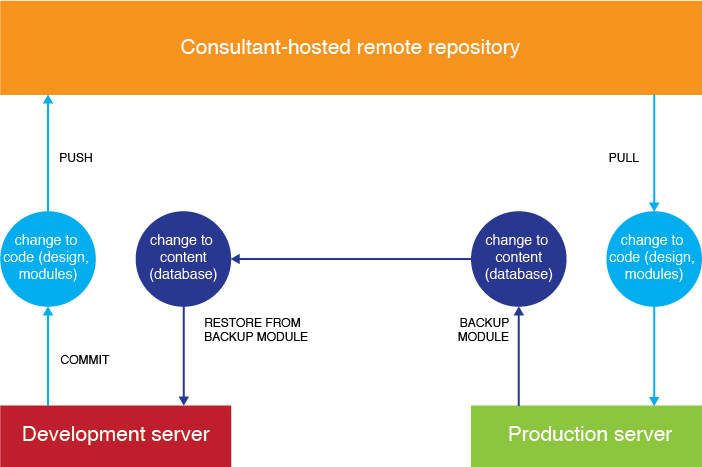
One Friday night a few weeks ago, all was peaceful here in the library. Everyone else had left, the lights were dimmed, and I was wrapping up a few last things before heading out to my weekend. I had done a few tweaks to the site’s dropdown menu CSS, and as I put on my scarf and coat, I casually pushed them from our development server’s Git repository to our remote master repo, then pulled the commits down to our production server.
I reloaded the library webpage.
It had gone completely blank.
As the panic slowly seeped into my bloodstream, I reloaded again and again, even looked at the source code — nothing, not even a space or error message.
Reverting
I had never rolled back any changes before, and the Git cheat sheet I have tacked to my wall didn’t have enough information about undoing mistakes to make me comfortable about rushing off a command. I called our Drupal consultant, who answered his cell phone while driving and spoke in a calming voice about how this is why we use version control, just revert to a safe commit, and it will all be okay.
Our commits are logged and easily readable in an Unfuddle project, so I peered at that and picked out what I knew to be the previous, safe commit, and entered this commend:
sudo git reset --hard 5154951c5a3a6a9211ba68268c6159c51cdb5f58
Every StackExchange thread featuring this command also included dire warnings that had previously frightened me away from using it, but if you really do want to wipe out changes in your local repository (in this case, whatever had just been pulled down to our production server), this is how you do it.
The site came back up as it had been before, after maybe five or ten minutes of downtime. I breathed a little easier and left for the weekend.
Investigating
But why had it gone blank? This was what I had to look into when I got back. If I pulled the most up-to-date commits down from the remote repo again, the site would still blank out. (I knew because I tried, hoping the WSoD had been a fluke. It wasn’t.) There were 60 changed files in the commit, mostly CSS, PDFs, and files for two non-essential modules. Even weirder, why was the up-to-date dev site totally fine? Until we fixed whatever was wrong on the production site, we’d have to pause development.
Drupal’s help pages have a list of common problems that case the White Screen of Death. It’s thorough but not complete. We went about troubleshooting at times when site use was low, so a few seconds of downtime wouldn’t be too disruptive. We still couldn’t tell if it was a server problem or something in those 60 files, so we started with these:
- Out of PHP memory?
- Already at 128 MB, double recommended amount
- No more space on virtual machine?
- Have around 30 GB left, not the problem
- Restart production server?
- Pulled from remote repo, then restarted server, still WSOD
- PHP execution time limit too low?
- Dev is 600 seconds, production is 30; changed to 600s, still WSOD
- Change settings file to display error when site goes blank after pull
- Message on blank site: Fatal error: require_once(): Failed opening required ‘…/sites/all/modules/admin_menu/admin_views/plugins/views_plugin_display_system.inc’ (include_path=’.:/usr/share/php:/usr/share/pear’) in …/includes/bootstrap.inc on line 3066
This error matched our server logs and Drupal error reports. The file that required opening had been deleted in the toxic commit, but at first it didn’t seem like that would be the problem. The Admin Views module is only visible to logged-in administrative users who want a more tricked-out menu bar at the top of their screens — why would it bring the site down?
In exasperation, I disabled the Admin Views module and tried again to pull down — and voilà, the site was still there, updated, and looked fine. Apparently, that was all I had to do: turn off the module causing problems so the site code wouldn’t quit out on me.
If it were a more essential module (not just one for a few admins’ convenience), we would have had to look into this issue further. For now, having caused enough headaches for myself, I’ll leave well enough alone.
Related post:
Using Drupal and Git for a library website
 On Global Women Wikipedia Write-In Day, I was extremely impressed with user Dsp13’s lists of red links — lists of notable women that hadn’t yet been written about on Wikipedia. I used that page as a springboard to write about some notable women in American history, like the wonderful Agnes Surriage Frankland. Dsp13 took these lists of names from resources like Famous American Women: A Biographical Dictionary, signifying the notability of the listed names and giving editors a place to start their research.
On Global Women Wikipedia Write-In Day, I was extremely impressed with user Dsp13’s lists of red links — lists of notable women that hadn’t yet been written about on Wikipedia. I used that page as a springboard to write about some notable women in American history, like the wonderful Agnes Surriage Frankland. Dsp13 took these lists of names from resources like Famous American Women: A Biographical Dictionary, signifying the notability of the listed names and giving editors a place to start their research.