TL;DR: I Bootstrapped lib.jjay.cc, a Library backup site with the links to online resources, hosted on my personal webspace with an official-ish domain name.
—
Over this past weekend, the John Jay College network went down. It was pretty serious: no one off-campus could access the main College website for a while, and even when that went back up, the Library website was down for about half the weekend. Yikes!
I had done two very lucky things earlier in the month:
- bought the domain name jjay.cc, hosted on my personal web space
- attended Junior Tidal’s Bootstrap workshop at BMCC
I’d bought jjay.cc on a whim. I’d proposed that the John Jay web department buy it as a shortlinker, and when they showed no interest, I bought it myself ($10, why not!) and have been using it as a way to shortlink Library content. (More on customizing Bit.ly later.) It looks official-ish, and no one has to know it’s on the same webspace as my other goofy websites.
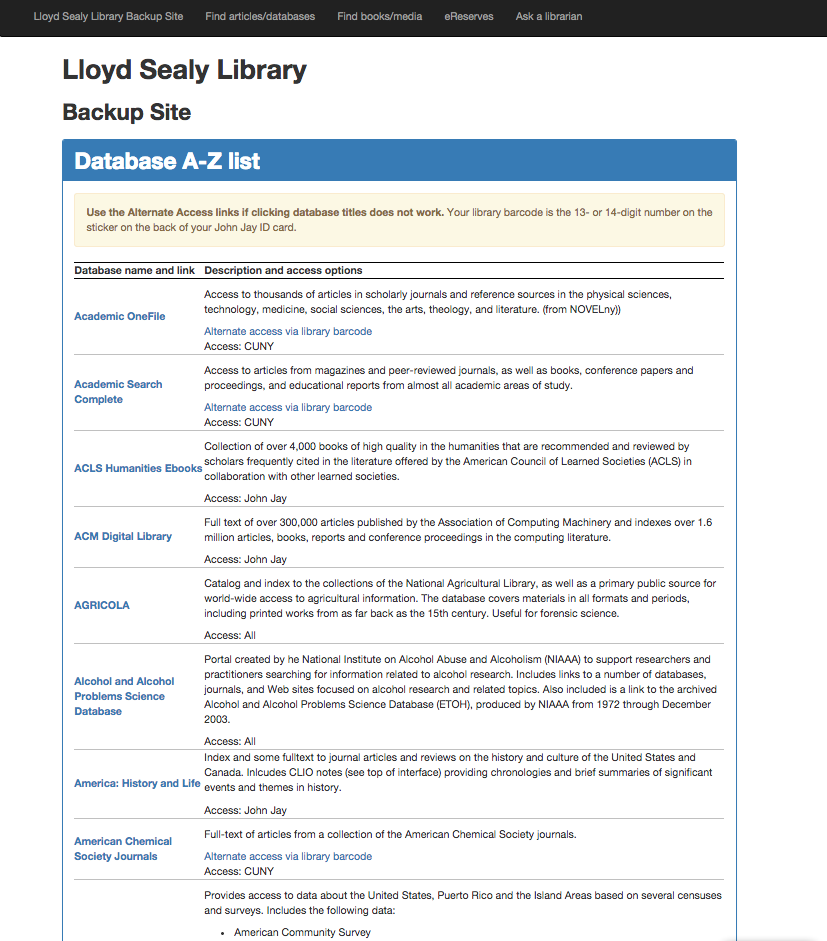
I owe a shout-out to Val Forrestal, who once gave a talk at METRO about setting up an emergency library site after getting hacked. I’d always thought, hey, I should do that sometime, just in case. And then, on Saturday, the flurry of emails about the campus-wide network issues seemed dire, and it was time. So I whipped up the Lloyd Sealy Library Emergency Backup site at lib.jjay.cc:

With a second page for the database A-Z list:
How I made the site
I made a basic Bootstrap template. “Bootstrapping” just means copying and pasting various parts of the Bootstrap framework. I used the navbar, panels, and tables. What’s nice is that everything is already styled and mobile-friendly. I only had to work on two HTML files.
The on-campus network was still functioning, thank goodness, so I VPN’d in to copy the HTML from the normal library site. No need to do anything new when all the code’s already done. EZproxy was also intermittently inaccessible, but luckily, students can also use their library barcodes to log into databases that CUNY subscribes to. We noted that fact on the backup site.
I use Dreamhost as my web host and domain registration service. I created a subdomain, lib.jjay.cc, and used my usual FTP login with Transmit to upload the files. I also uploaded a restrictive robots.txt file so that this backup site would never show up on Google.
It took me under an hour to set it up. We publicized the backup site on social media and got a few grateful responses. We were in touch with the John Jay webmaster about changing the link to the library on the main college site, in case IT told us the network issues would take much longer to resolve. In the end, we just waited it out. And now we’ve got a backup site, should anything go wrong with the network or our servers. (Knock on wood.)
Takeaways: make a stripped-down version of your library website and keep it somewhere safe, somewhere you can access it on- or off-campus. And if you don’t mind spending an extra $10/yr, it might be worth it to buy an official-looking but unofficial domain name, just in case.
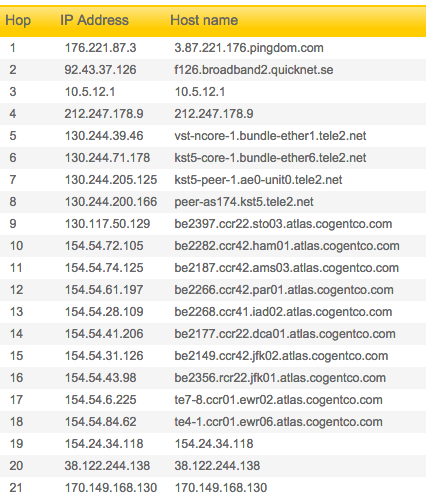
 I designed a new 30-minute workshop for students this semester called “See through the internet: 8 questions & answers about how the internet really works.” I’ve given it a total of 1 time so far, to 2 people, today, but am scheduled for several more later in the semester. The subject matter is close to my heart, though, so I look for any opportunity to share this material. Perhaps you’ll find it useful, too. Here’s a draft summary of the workshop curriculum. Note that it is aimed as an intro for undergrad students.
I designed a new 30-minute workshop for students this semester called “See through the internet: 8 questions & answers about how the internet really works.” I’ve given it a total of 1 time so far, to 2 people, today, but am scheduled for several more later in the semester. The subject matter is close to my heart, though, so I look for any opportunity to share this material. Perhaps you’ll find it useful, too. Here’s a draft summary of the workshop curriculum. Note that it is aimed as an intro for undergrad students.